- 1 stark positive Korrelation
- 0 keine Korrelation
- -1 stark negative Korrelation
- Struktur des Konzept des ML Modell visualisieren
- Auswahl der Features für das ML Modell
- Trifft nicht auf Deep Learning zu
||x|y|x*y|x2|
|---|---|---|---|---|
||1|2|2|1|
||2|3|6|4|
||3|5|15|9|
||4|4|16|16|
||5|6|30|25|
|$$\sum$$|**15**|**20**|**69**|**55**|
2. *c* Wert berechnen
$$
c = \frac{\sum_y * \sum_x - \sum_x * \sum_{xy}}{n(\sum_{x^2}) - (\sum_x)^2} \\[1em]
c = \frac{20 * 55 - 15 * 69}{5*55 - 15^2} = 1.3
$$
3. *m* Wert berechnen
$$
m = \frac{n(\sum_{xy}) - \sum_x * \sum_y}{n(\sum_{x^2} - (\sum_x)^2)} \\[1em]
m = \frac{5 * 69 - 15 * 20}{5 * 55 - 15^2} = 0.9
$$
4. Werte in Formel einsetzen
$$
\hat{y} = mx+c \\
\hat{y} = 0.9x+1.3
$$
5. Funktionsgraphen mit Regressionsgerade Zeichnen
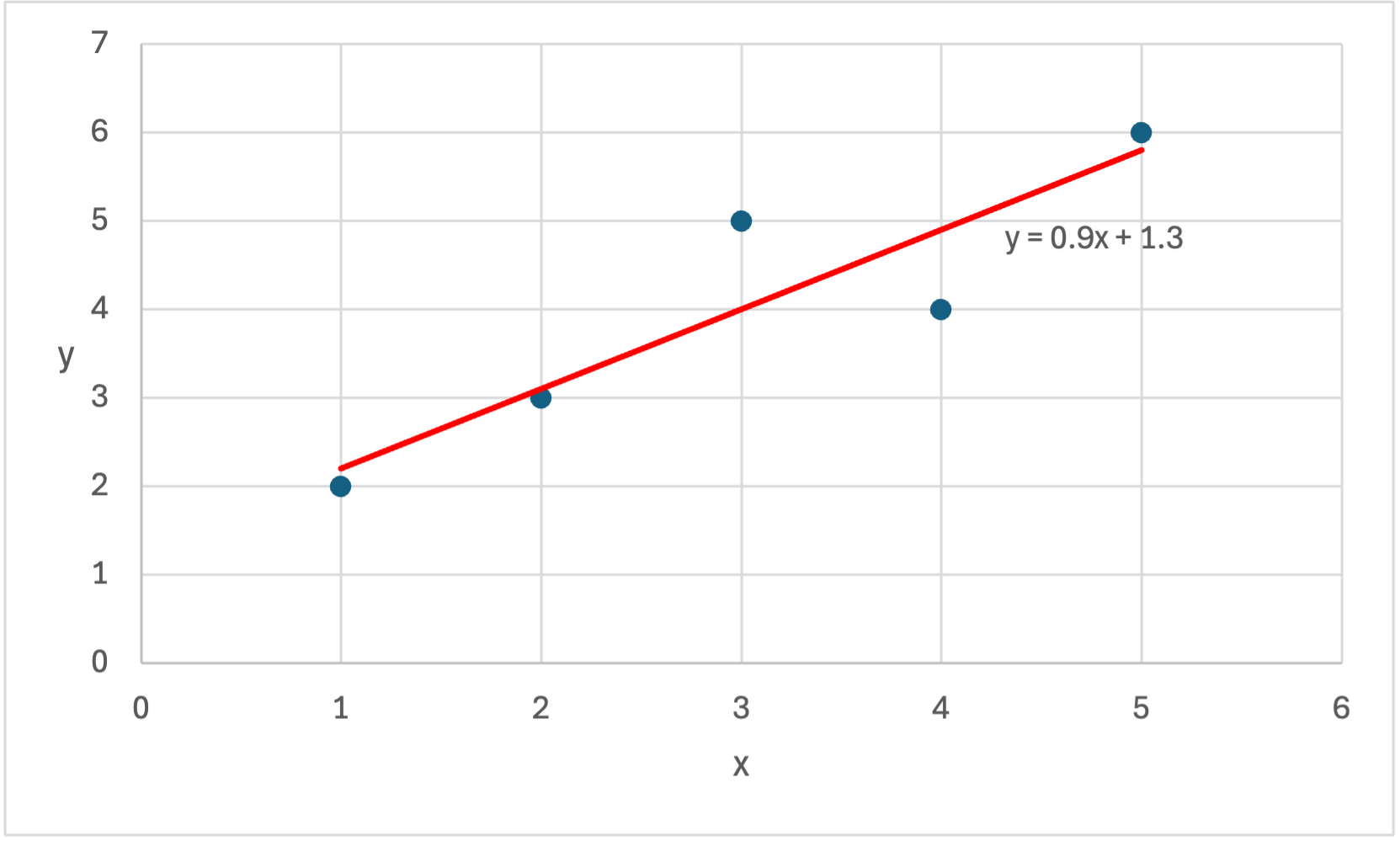
0.81 bedeutet, dass viele der Datenpunkte in der Nähe der Regressionsgerade sind.
## Klassifikation
|Begriff|Beschreibung|
|---|---|
|Binäre Klassifikatoren|Ein binärer Klassifikator unterscheidet zwischen zwei Klassen. Z.B. "Ziffer ist 0" vs. "Ziffer ist nicht 0"|
|Logistische Regression|Die logistische Regression ist eine Form der Regressionsanalyse , die man verwendet, um ein nominalskaliertes, kategoriales Kriterium vorherzusagen. Das bedeutet, man verwendet die logistische Regression immer dann, wenn die abhängige Variable nur ein paar wenige, gleichrangige Ausprägungen hat. Ein Beispiel für ein kategoriales Kriterium wäre etwa der Ausgang einer Aufnahmeprüfung, bei der man nur entweder „angenommen“ oder „abgelehnt“ werden kann.|
|Logistische Regression vs. lineare Regression|Im Gegensatz zur linearen Regression sagt man bei der logistischen Regression nicht die konkreten Werte des Kriteriums vorher. Stattdessen schätzt man, wie wahrscheinlich es ist, dass eine Person in die eine oder die andere Kategorie des Kriteriums fällt. So könntest man etwa vorhersagen, wie wahrscheinlich es ist, dass eine Person mit einem IQ von 112 die Aufnahmeprüfung bestehen wird. Für die Vorhersage verwendet man auch bei der logistischen Regression eine Regressionsgleichung. Überträgt man diese Regressionsgleichung in ein Koordinatensystem, so erhält man die charakteristische Kurve der logistischen Regression. An ihr kann man abschätzen, wie wahrscheinlich eine Merkmalsausprägung des Kriteriums für eine Person mit einem bestimmten Prädiktorwert ist und wie gut das Modell zu deinen Daten passt. Die Funktion der logistischen Regression sieht so aus: 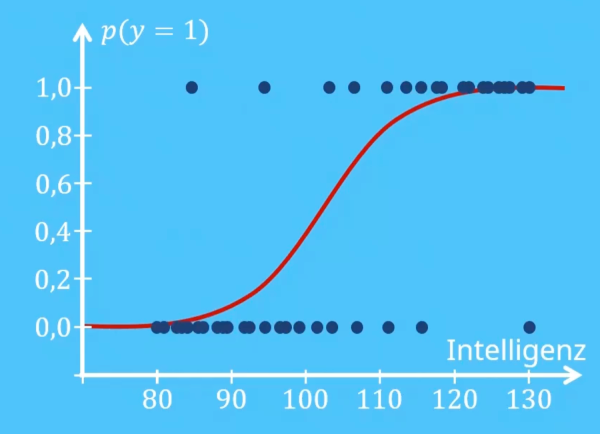|
|Stochastisches Gradientverfahren (SGD)|- Iteratives Optimierungsverfahren
- Parameter verändern
- Minimum der Verlustfunktion finden
- SGDClassifier in Scikit-Learn
- Lineare Support Vector Machine (SVM)
- Logistic Regression
- Eingesetzt in…
- Machine Learning
- Deep Learning
- Reinforcement Learning
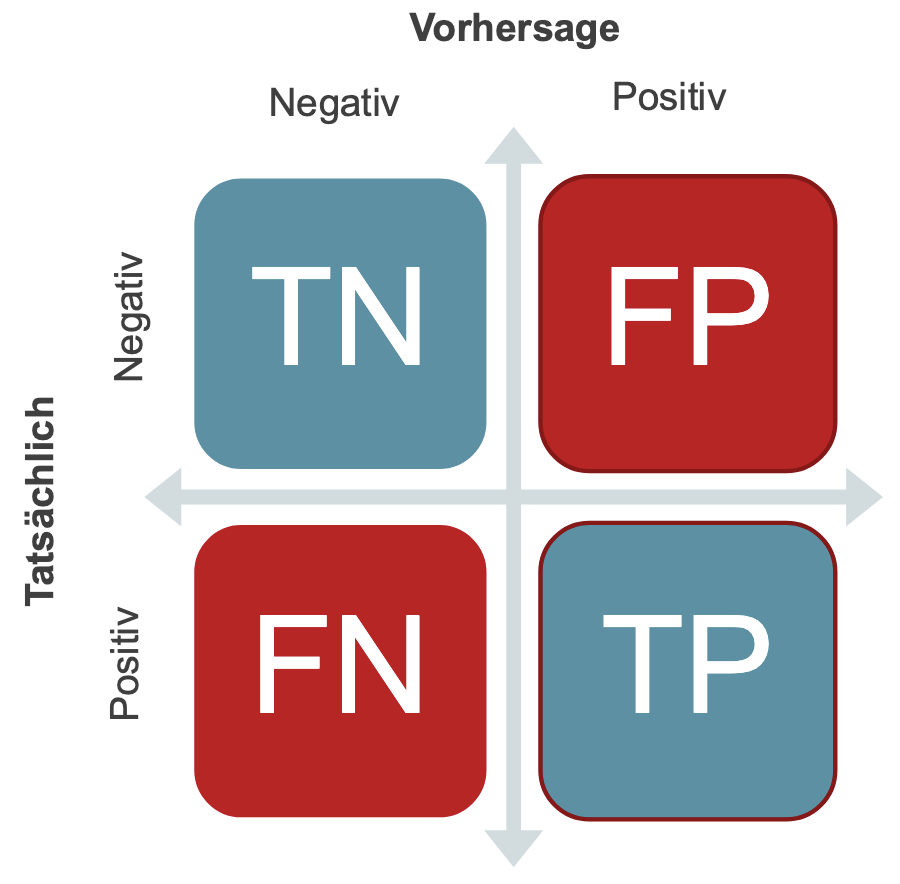 |
|Precision (Relevanz)|Gibt den Anteil der korrekt als positiv klassifizierten Ergebnisse an der Gesamtheit der als positiv klassifizierten Ergebnisse an $\large precision = \frac{tp}{tp+fp} $|
|Recall (Sensivität)|Gibt die Wahrscheinlichkeit an, mit der ein positives Objekt korrekt als positiv klassifiziert wird. $\large recall = \frac{tp}{tp+fn} $|
|F1|Der F1-Wert ist der harmonische Mittelwert (eine Art Durchschnitt) von Precision und Recall. Dieser Messwert gleicht die Bedeutung von Precision und Recall aus und ist für Datasets mit unausgeglichenen Klassen besser geeignet als die Genauigkeit. $\large \\ f1=2*\frac{precision * recall}{precision + recall} $|
|ROC-Kurve|Bewertung der Trennschärfe eines binären Klassifikators über verschiedene Schwellenwerte.
|
|Precision (Relevanz)|Gibt den Anteil der korrekt als positiv klassifizierten Ergebnisse an der Gesamtheit der als positiv klassifizierten Ergebnisse an $\large precision = \frac{tp}{tp+fp} $|
|Recall (Sensivität)|Gibt die Wahrscheinlichkeit an, mit der ein positives Objekt korrekt als positiv klassifiziert wird. $\large recall = \frac{tp}{tp+fn} $|
|F1|Der F1-Wert ist der harmonische Mittelwert (eine Art Durchschnitt) von Precision und Recall. Dieser Messwert gleicht die Bedeutung von Precision und Recall aus und ist für Datasets mit unausgeglichenen Klassen besser geeignet als die Genauigkeit. $\large \\ f1=2*\frac{precision * recall}{precision + recall} $|
|ROC-Kurve|Bewertung der Trennschärfe eines binären Klassifikators über verschiedene Schwellenwerte. 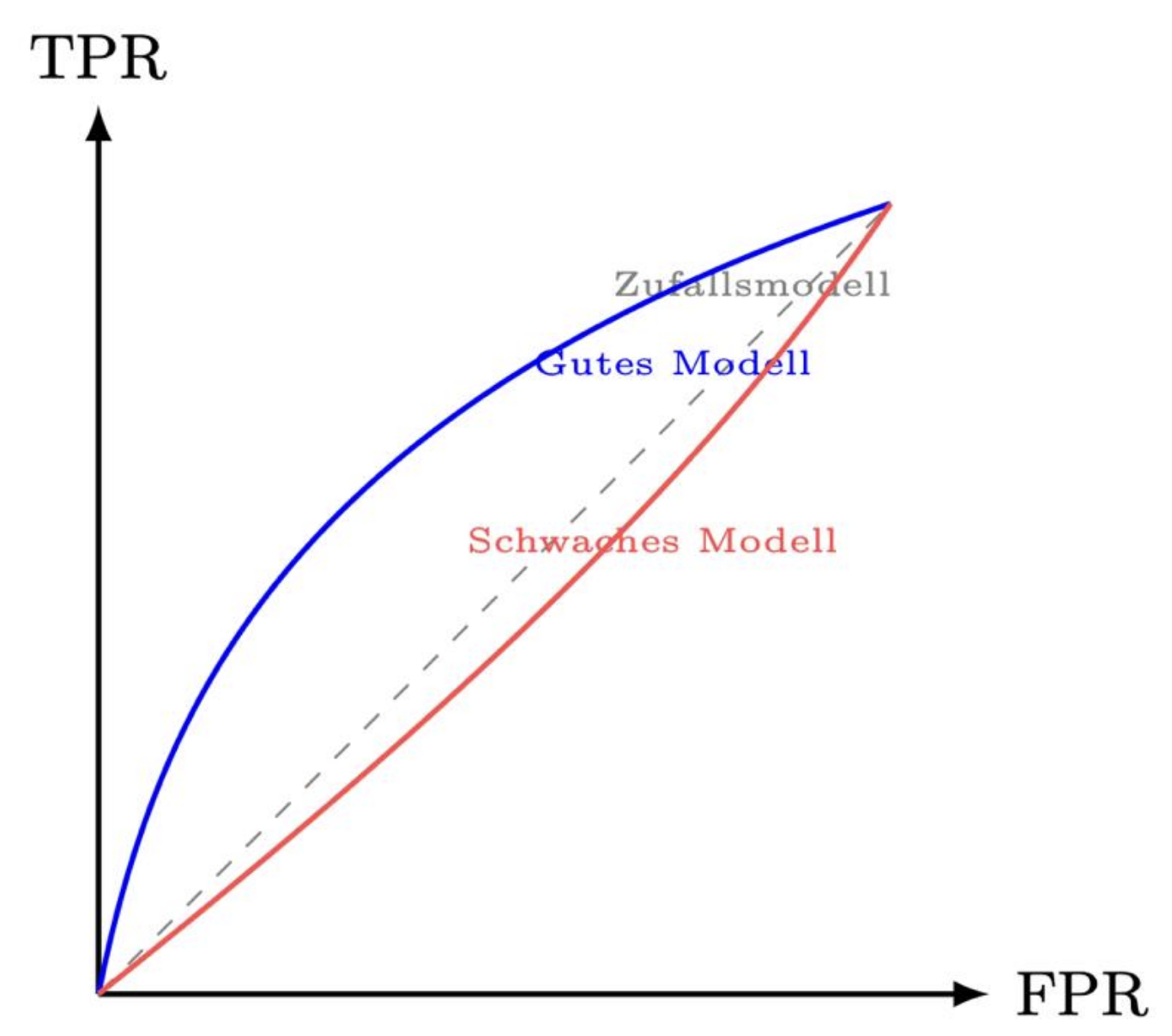 |
|TPR (True Positive Rate)|Beschreibt, wie viele der tatsächlich positiven Beispiele korrekt erkannt wurden. Sie entspricht dem Recall. Eine TPR von 1.0 bedeutet: alle positiven Beispiele wurden richtig erkannt. $\large TPR = \frac{TP}{TP+FN} $|
|FPR (False Positive Rate)|Die FPR (False Positive Rate) misst, wie viele der negativen Beispiele fälschlich als positiv klassifiziert wurden. Eine FPR von 0.2 bedeutet: 20 % der negativen Beispiele wurden falsch als positiv erkannt. $\large FPR = \frac{FP}{FP+TN} $|
|Multiclass Classification|Multiclass Classification umfasst Datensätze mit mehreren Klassenbezeichnungen.
|
|TPR (True Positive Rate)|Beschreibt, wie viele der tatsächlich positiven Beispiele korrekt erkannt wurden. Sie entspricht dem Recall. Eine TPR von 1.0 bedeutet: alle positiven Beispiele wurden richtig erkannt. $\large TPR = \frac{TP}{TP+FN} $|
|FPR (False Positive Rate)|Die FPR (False Positive Rate) misst, wie viele der negativen Beispiele fälschlich als positiv klassifiziert wurden. Eine FPR von 0.2 bedeutet: 20 % der negativen Beispiele wurden falsch als positiv erkannt. $\large FPR = \frac{FP}{FP+TN} $|
|Multiclass Classification|Multiclass Classification umfasst Datensätze mit mehreren Klassenbezeichnungen. 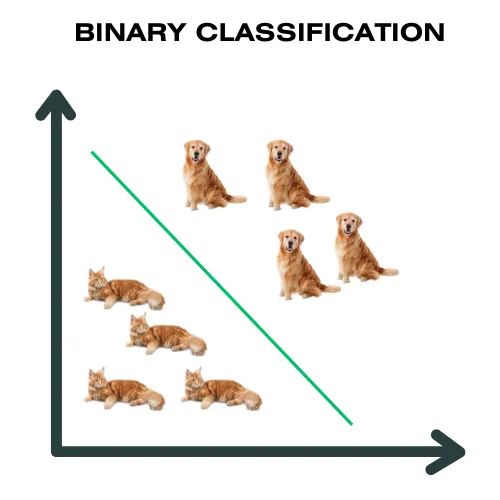
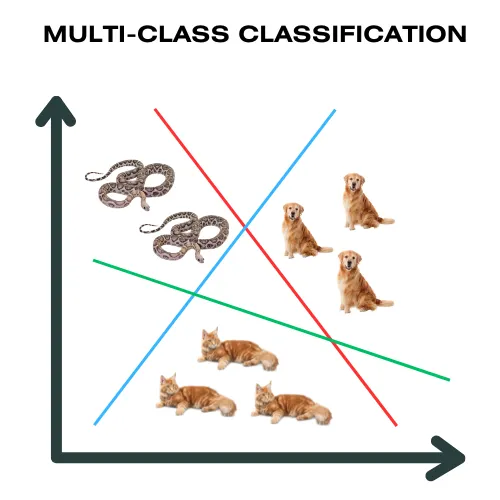
|
|One vs. The Rest|Beim One vs. Rest Klassifizierungsansatz, der auf einen Datensatz mit N unterschiedlichen Klassen zugeschnitten ist, werden N binäre Klassifikatoren generiert, die jeweils einer bestimmten Klasse entsprechen. Die Anzahl der Klassifikatoren entspricht der Anzahl der eindeutigen Klassenbezeichnungen, die im Datensatz vorhanden sind. 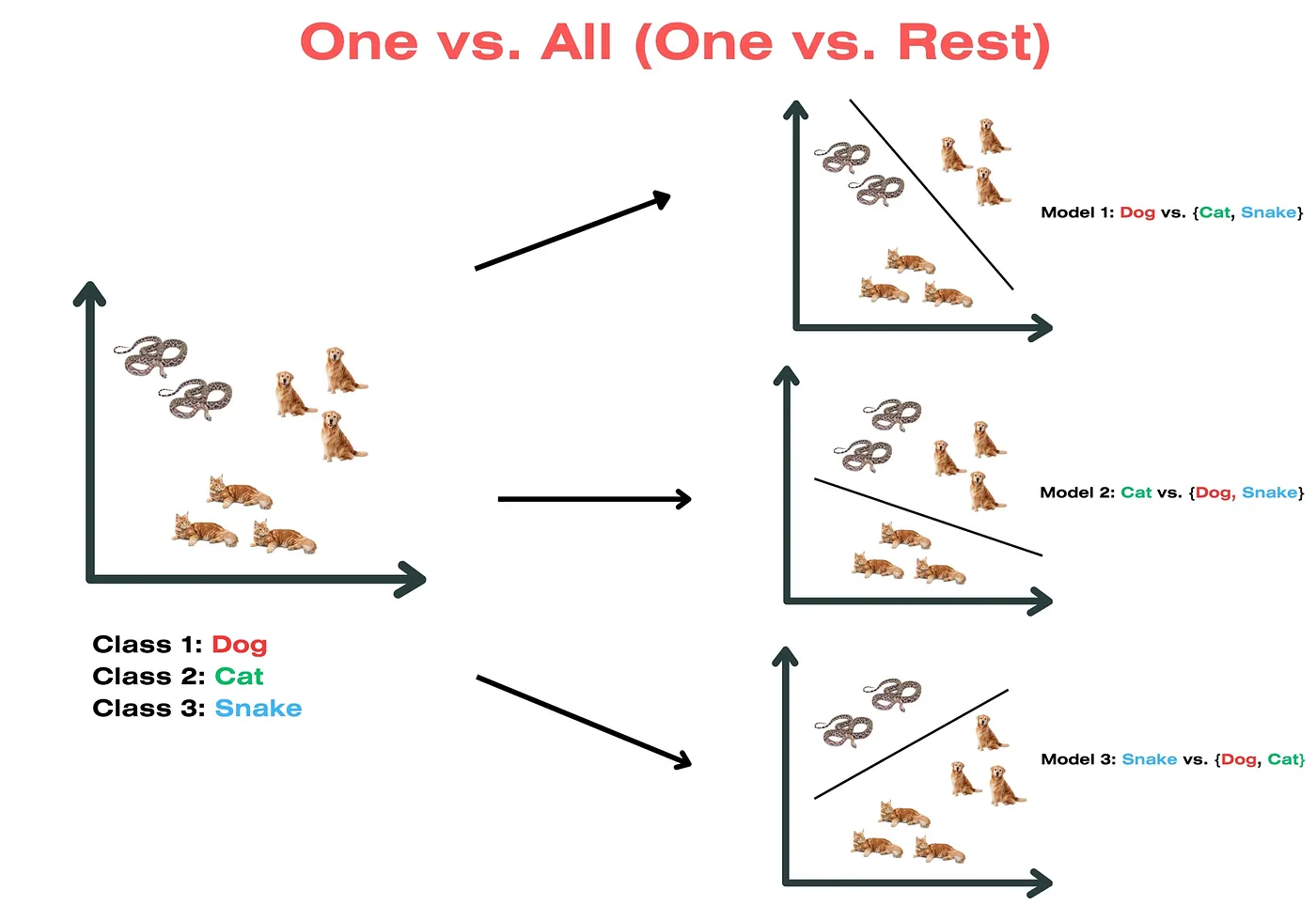 |
|One vs. One|Bei der One vs. One Klassifizierungsstrategie, die auf einen Datensatz mit N unterschiedlichen Klassen zugeschnitten ist, werden insgesamt N * (N-1) / 2 binäre Klassifikatoren generiert. Bei diesem Ansatz wird für jedes mögliche Klassenpaar ein binärer Klassifikator erstellt.
|
|One vs. One|Bei der One vs. One Klassifizierungsstrategie, die auf einen Datensatz mit N unterschiedlichen Klassen zugeschnitten ist, werden insgesamt N * (N-1) / 2 binäre Klassifikatoren generiert. Bei diesem Ansatz wird für jedes mögliche Klassenpaar ein binärer Klassifikator erstellt.
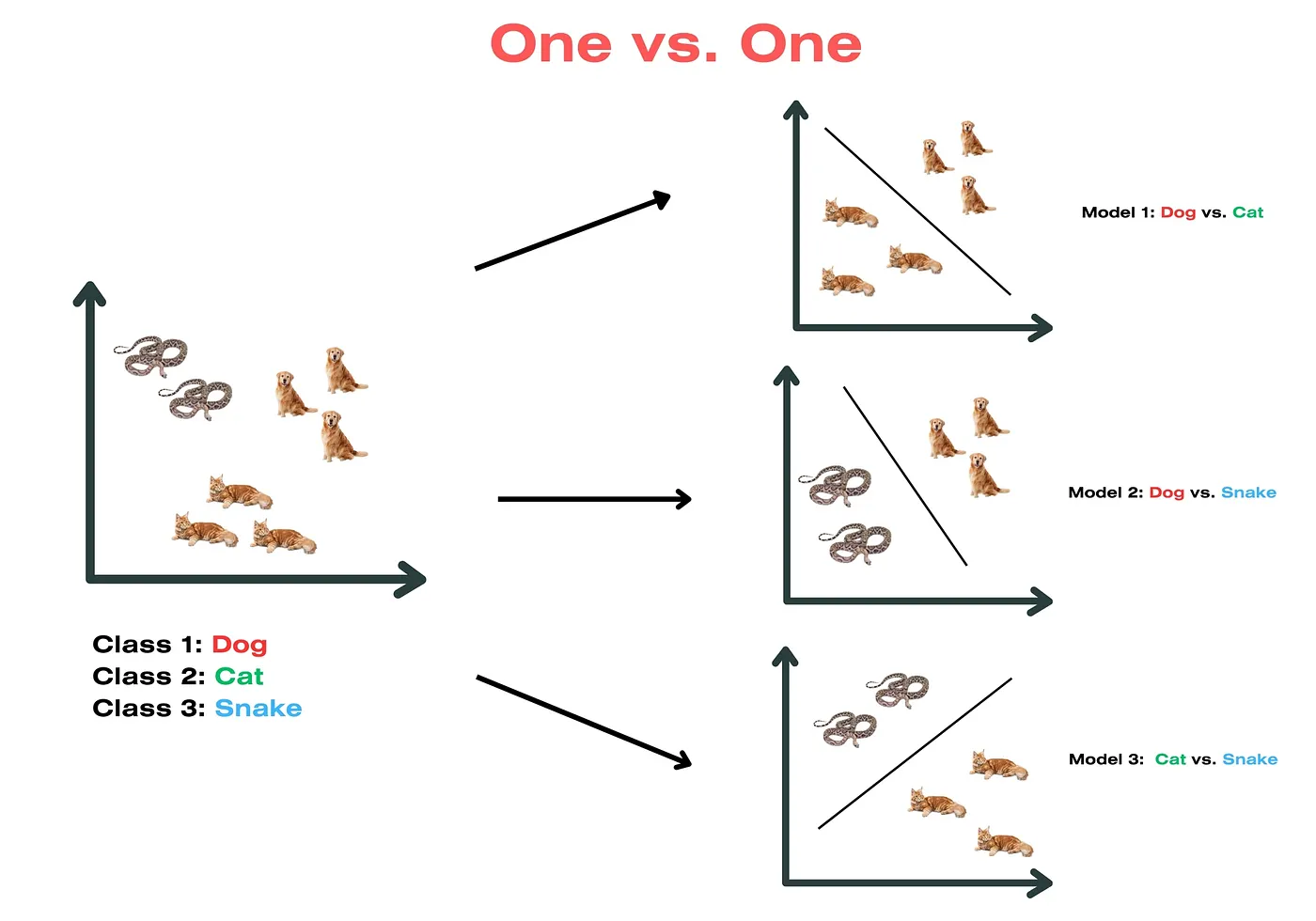 |
## Unsupervised Learning Clustering
|Begriff|Beschreibung|
|---|---|
|Clustering|Clustering kann als das wichtigste Problem des unüberwachten Lernens angesehen werden. Es befasst sich mit der Suche nach einer Struktur in einer Sammlung unbeschrifteter Daten. Eine grobe Definition von Clustering könnte der Prozess der Organisation von Objekten in Gruppen sein, deren Mitglieder sich in irgendeiner Weise ähneln. Ein Cluster ist daher eine Sammlung von Objekten, die sich untereinander ähneln und sich von den Objekten anderer Cluster unterscheiden.|
|Distanzmasse|Festzustellen, welche Datenpunkte innerhalb eines Clusters sich ähnlicher sind als andere. Distanzmasse werden tendenziell kleiner, je ähnlicher zwei Punkte sich sind.
|
## Unsupervised Learning Clustering
|Begriff|Beschreibung|
|---|---|
|Clustering|Clustering kann als das wichtigste Problem des unüberwachten Lernens angesehen werden. Es befasst sich mit der Suche nach einer Struktur in einer Sammlung unbeschrifteter Daten. Eine grobe Definition von Clustering könnte der Prozess der Organisation von Objekten in Gruppen sein, deren Mitglieder sich in irgendeiner Weise ähneln. Ein Cluster ist daher eine Sammlung von Objekten, die sich untereinander ähneln und sich von den Objekten anderer Cluster unterscheiden.|
|Distanzmasse|Festzustellen, welche Datenpunkte innerhalb eines Clusters sich ähnlicher sind als andere. Distanzmasse werden tendenziell kleiner, je ähnlicher zwei Punkte sich sind.
Beispiele:
Beispiele:
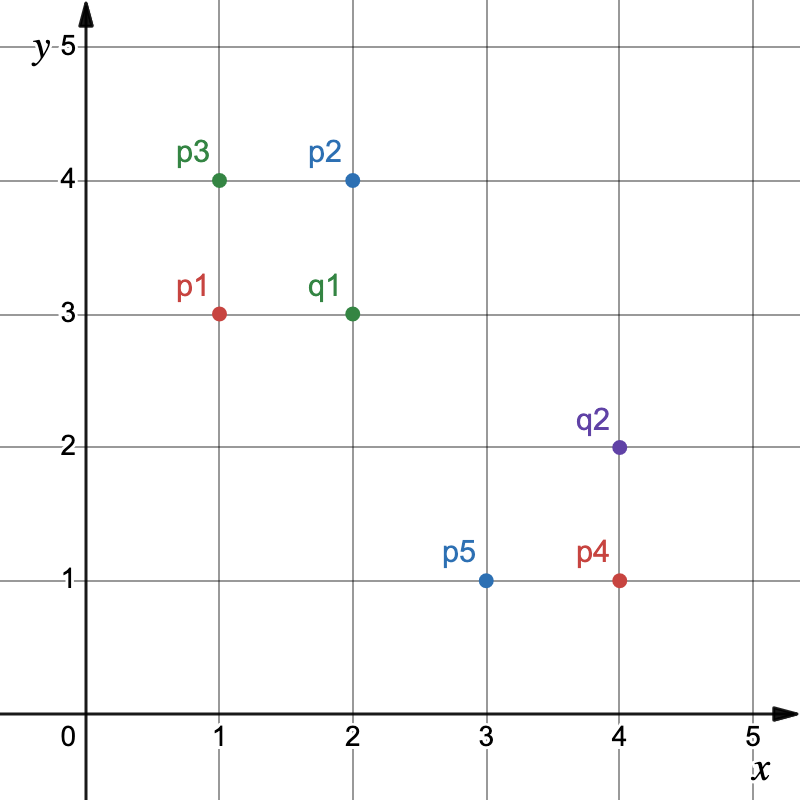 1. Quadrierte euklidische Distanz zwischen Punkte und Clusterzentren berechnen
$$
d(x,y)=\sqrt{\sum_{i=1}^{n} (x_i-y_i)^2}^2 = \sum_{i=1}^{n} (x_i-y_i)^2
$$
$$
d(p1,q1)=(1-2)^2+(3-3)^2=1
$$
$$
d(p2,q1)=(2-2)^2+(4-3)^2=1
$$
$$
d(p3,q1)=(1-2)^2+(4-3)^2=2
$$
$$
d(p4,q1)=(4-2)^2+(1-3)^2=8
$$
$$
d(p5,q1)=(3-2)^2+(1-3)^2=5
$$
$$
d(p1,q2)=(1-4)^2+(3-2)^2=10
$$
$$
d(p2,q2)=(2-4)^2+(4-2)^2=8
$$
$$
d(p3,q2)=(1-4)^2+(4-2)^2=13
$$
$$
d(p4,q2)=(4-4)^2+(1-2)^2=1
$$
$$
d(p5,q2)=(3-4)^2+(1-2)^2=2
$$
1. Quadrierte euklidische Distanz zwischen Punkte und Clusterzentren berechnen
$$
d(x,y)=\sqrt{\sum_{i=1}^{n} (x_i-y_i)^2}^2 = \sum_{i=1}^{n} (x_i-y_i)^2
$$
$$
d(p1,q1)=(1-2)^2+(3-3)^2=1
$$
$$
d(p2,q1)=(2-2)^2+(4-3)^2=1
$$
$$
d(p3,q1)=(1-2)^2+(4-3)^2=2
$$
$$
d(p4,q1)=(4-2)^2+(1-3)^2=8
$$
$$
d(p5,q1)=(3-2)^2+(1-3)^2=5
$$
$$
d(p1,q2)=(1-4)^2+(3-2)^2=10
$$
$$
d(p2,q2)=(2-4)^2+(4-2)^2=8
$$
$$
d(p3,q2)=(1-4)^2+(4-2)^2=13
$$
$$
d(p4,q2)=(4-4)^2+(1-2)^2=1
$$
$$
d(p5,q2)=(3-4)^2+(1-2)^2=2
$$
 |Begriff|Beschreibung|
|---|---|
|Elbow-Method|Beim K-Means Clustering unterteilt der Algorithmus Daten in k Cluster, indem er die Abstände zwischen Punkten und ihren Clusterzentren minimiert. Die Entscheidung für das ideale k ist jedoch nicht einfach. Die Elbow-Methode hilft dabei, indem sie die Summenquadrate innerhalb der Cluster (WCSS) gegen steigende k-Werte aufträgt und nach einem Punkt sucht, an dem sich die Verbesserung verlangsamt. Dieser Punkt wird als „Elbow“ bezeichnet.
|Begriff|Beschreibung|
|---|---|
|Elbow-Method|Beim K-Means Clustering unterteilt der Algorithmus Daten in k Cluster, indem er die Abstände zwischen Punkten und ihren Clusterzentren minimiert. Die Entscheidung für das ideale k ist jedoch nicht einfach. Die Elbow-Methode hilft dabei, indem sie die Summenquadrate innerhalb der Cluster (WCSS) gegen steigende k-Werte aufträgt und nach einem Punkt sucht, an dem sich die Verbesserung verlangsamt. Dieser Punkt wird als „Elbow“ bezeichnet. 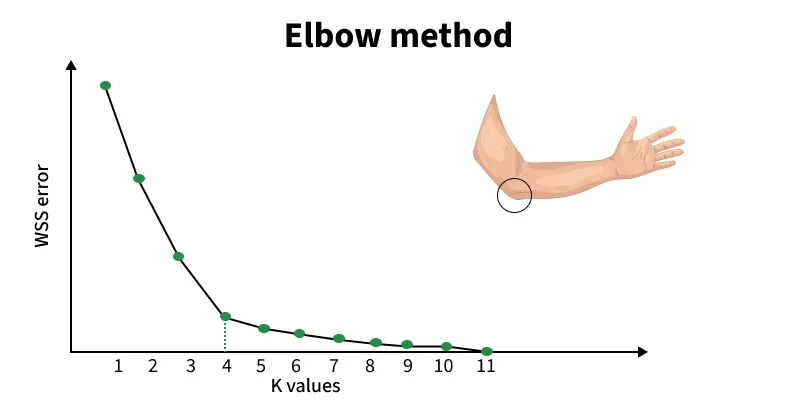
- Beliebig geformte Cluster: Cluster können jede beliebige Form annehmen, nicht nur kreisförmig oder konvex.
- Rauschen und Ausreißer: Es identifiziert und behandelt Rauschpunkte effektiv, ohne sie einem Cluster zuzuordnen.
|
|K-Means vs. Hierarchie vs. DBSCAN|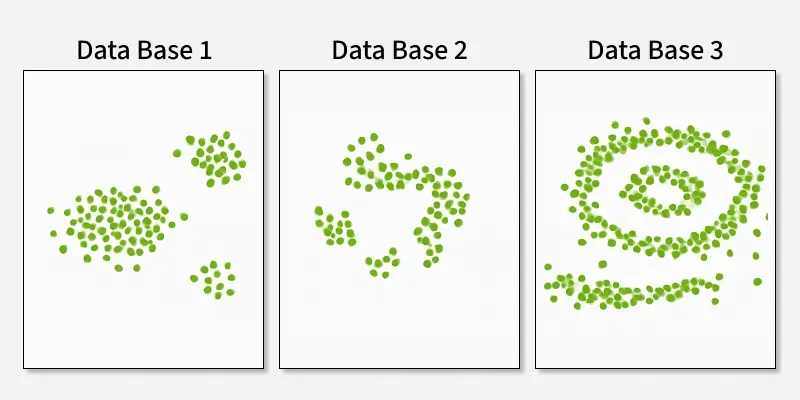 |
|
|
|One vs. One|Bei der One vs. One Klassifizierungsstrategie, die auf einen Datensatz mit N unterschiedlichen Klassen zugeschnitten ist, werden insgesamt N * (N-1) / 2 binäre Klassifikatoren generiert. Bei diesem Ansatz wird für jedes mögliche Klassenpaar ein binärer Klassifikator erstellt.|
## Unsupervised Learning Clustering
|Begriff|Beschreibung|
|---|---|
|Clustering|Clustering kann als das wichtigste Problem des unüberwachten Lernens angesehen werden. Es befasst sich mit der Suche nach einer Struktur in einer Sammlung unbeschrifteter Daten. Eine grobe Definition von Clustering könnte der Prozess der Organisation von Objekten in Gruppen sein, deren Mitglieder sich in irgendeiner Weise ähneln. Ein Cluster ist daher eine Sammlung von Objekten, die sich untereinander ähneln und sich von den Objekten anderer Cluster unterscheiden.|
|Distanzmasse|Festzustellen, welche Datenpunkte innerhalb eines Clusters sich ähnlicher sind als andere. Distanzmasse werden tendenziell kleiner, je ähnlicher zwei Punkte sich sind. Beispiele:
- Euklidische Distanz
- Minkowski Distanz
- Canberra Distanz
Beispiele:
- Cosinus Similarity
- Pearson Korrelationskoeffiziet
- Jaccard Koeffizient
||p1|p2|p3|p4|p5|
|---|---|---|---|---|---|
|**q1**|1|1|2|8|5|
|**q2**|10|8|13|1|2|
2. Punkte mittels Distanzfunktion zu Clusterzentren zuordnen
$$
q1=\{p1(1,3), p2(2,4), p3(1,4)\}
$$
$$
q2=\{p4(4,1), p5(3,1)\}
$$
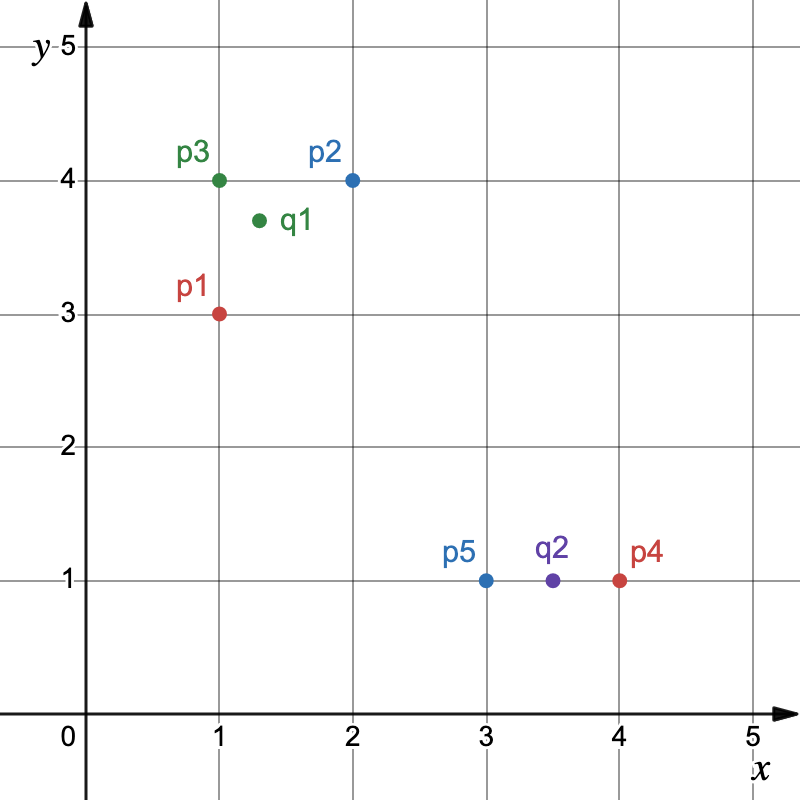
3. Neues Clusterzentrum berechnen
$$
\frac{\sum_{i=1}^n \vec{x_i}}{n}
$$
$$
\frac{
\begin{pmatrix}
1 \\
3
\end{pmatrix}
+
\begin{pmatrix}
2 \\
4
\end{pmatrix}
+
\begin{pmatrix}
1 \\
4
\end{pmatrix}
}{3}=\begin{pmatrix}1.3 \\3.7\end{pmatrix}
$$
$$
\frac{
\begin{pmatrix}
4 \\
1
\end{pmatrix}
+
\begin{pmatrix}
3 \\
1
\end{pmatrix}
}{2}=\begin{pmatrix}3.5 \\1\end{pmatrix}
$$
4. Clusterzentren neu plotten
|